Identifying the entities
Once you have downloaded the Wikipedia pages, you need to inspect the files to assemble the entity collection protocol. In this stage, things will revolve around the collector function. The aim is to generate a nested list comprising all the information that the index page provides for each legislator.
Exploring the HTMLs
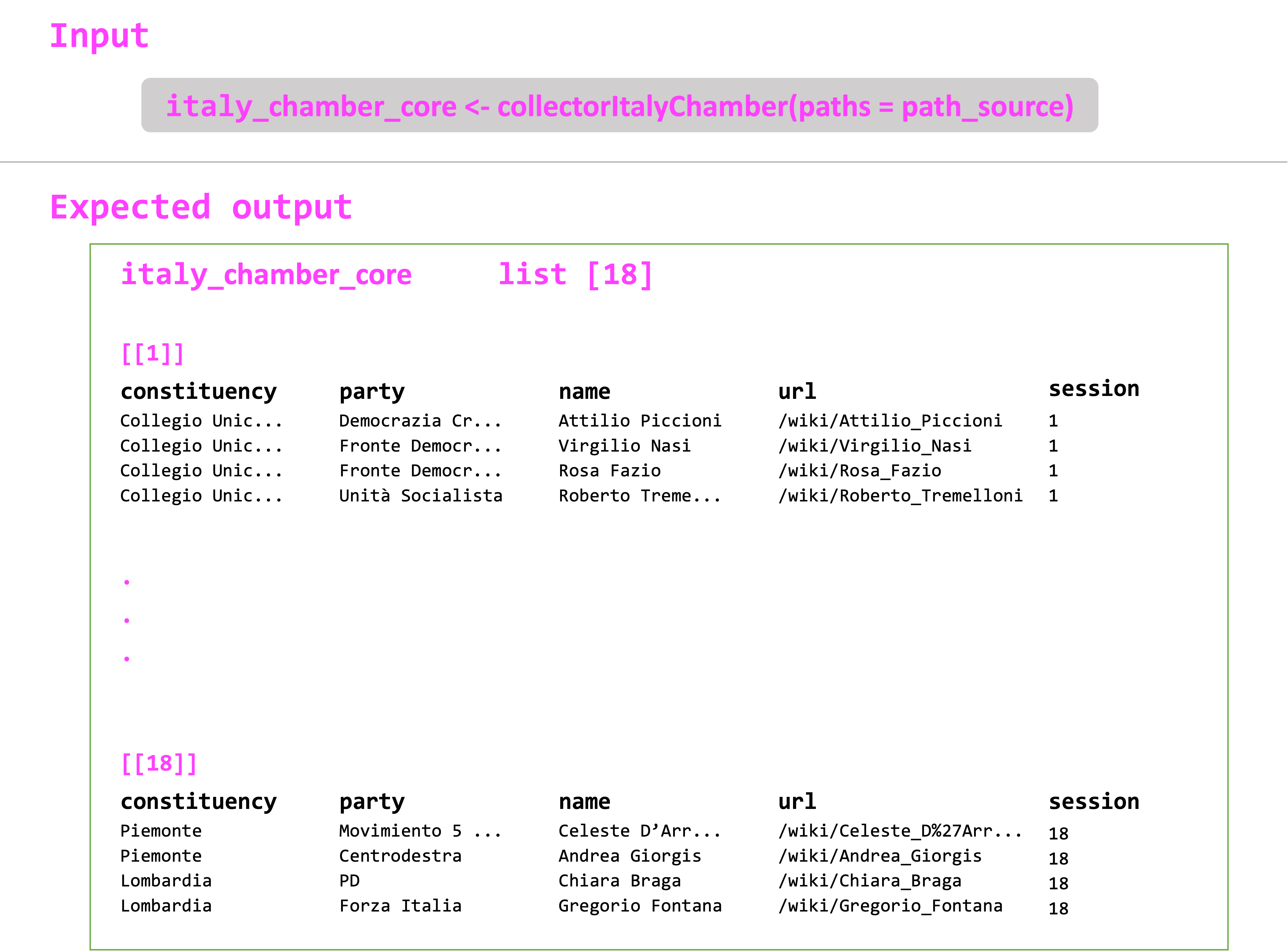
Take a look at the 1948 Chamber elections index page below. As you can see, there are three data points that you are interested in: Collegio (constituency), Lista (party), and Elleto (name of the legislator). If you scroll through the page, you can also notice that all the information is contained within a single table.
The code employs the the rvest package to load the html files into R. This is how the same site looks in the R environment.
parsed_html <- rvest::read_html("data/italy_chamber/html/1948_chamber_session_ITA.html")
parsed_html
## {html_document}
## <html class="client-nojs" lang="it" dir="ltr">
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">\n<meta charset="UTF-8">\n<title>Eletti alla Camera dei deputati nelle elepolitiche italia ...
## [2] <body class="mediawiki ltr sitedir-ltr mw-hide-empty-elt ns-0 ns-subject mw-editable page-Eletti_alla_Camera_dei_deputati_nelle_elezioni_politiche_italiane_del_1948 rootpa ...
Getting familiar with XPaths
You can inspect the structure of the HTML files through the browser. Let’s take the first legislator as an example. You can right click on the name and select Inspect. The code to render the page will appear on a panel in the browser with the attribute specific to the name we clicked on opened by default. In this case, it would be:
<a href="/wiki/Attilio_Piccioni" title="Attilio Piccioni">Attilio Piccioni</a>
As you can see, this <a> tag contains some data you are interested in. That is, the href attribute holds the path to the legislator’s Wikipedia page and the title attribute the name of the legislator.
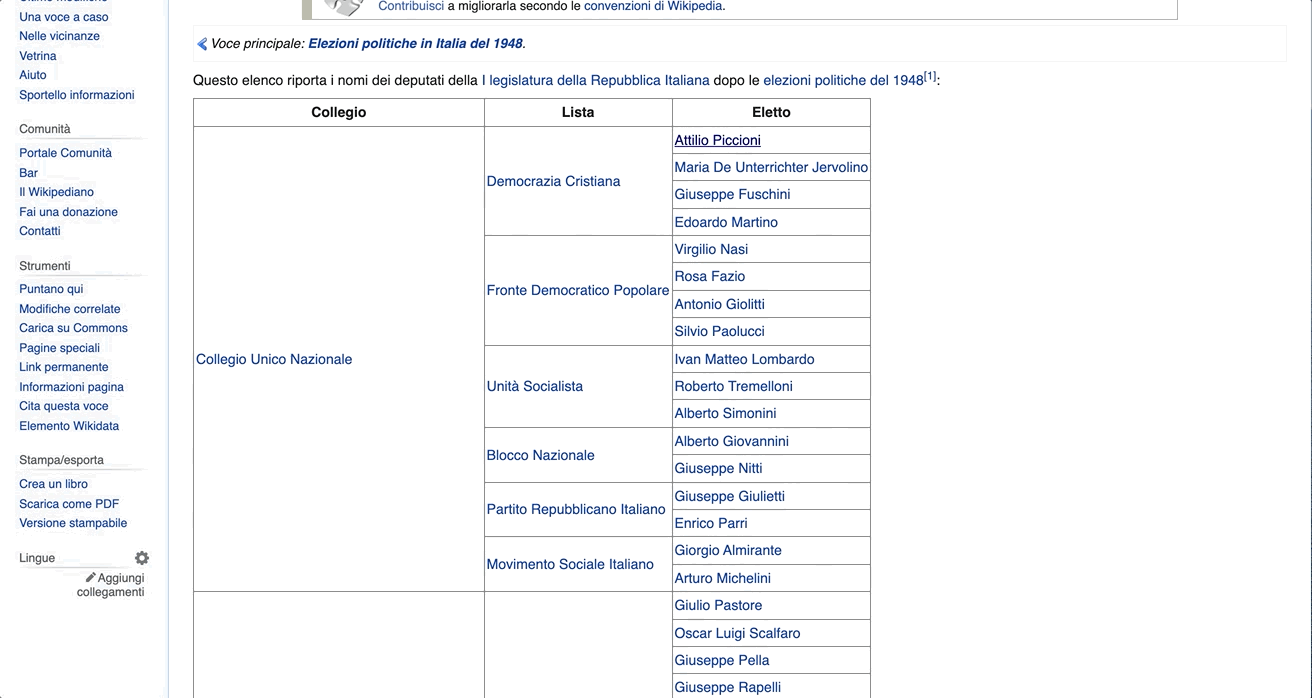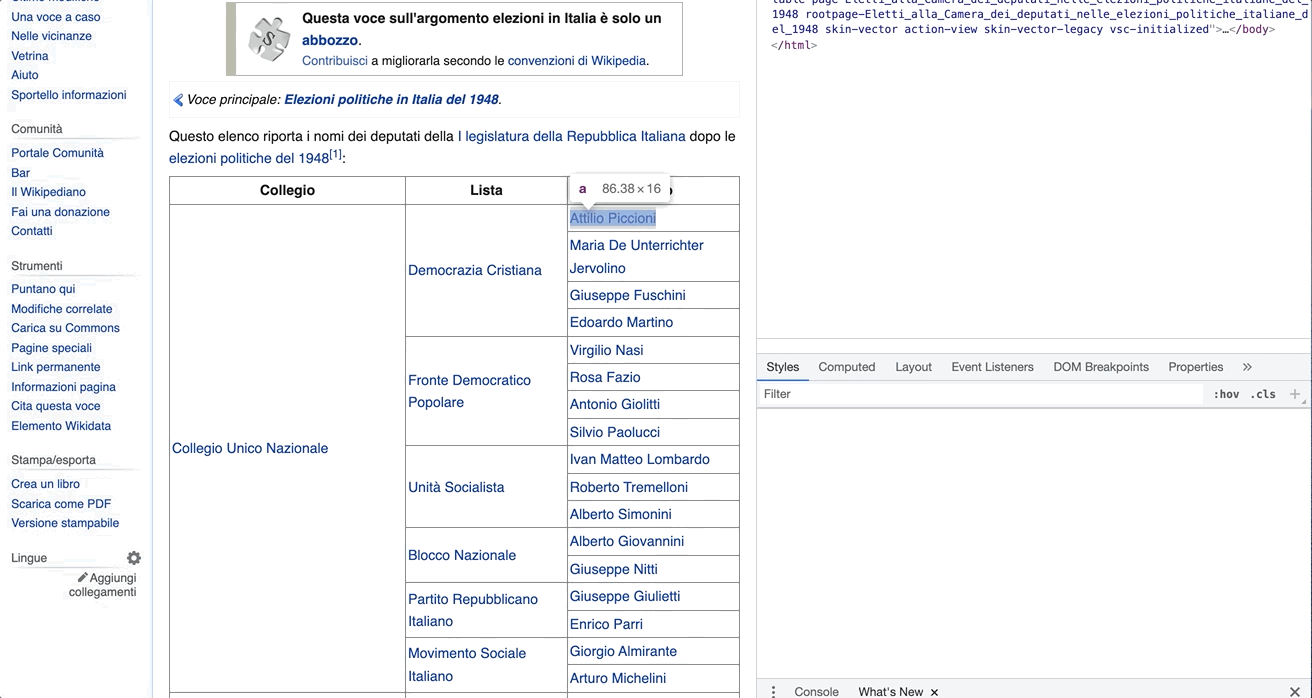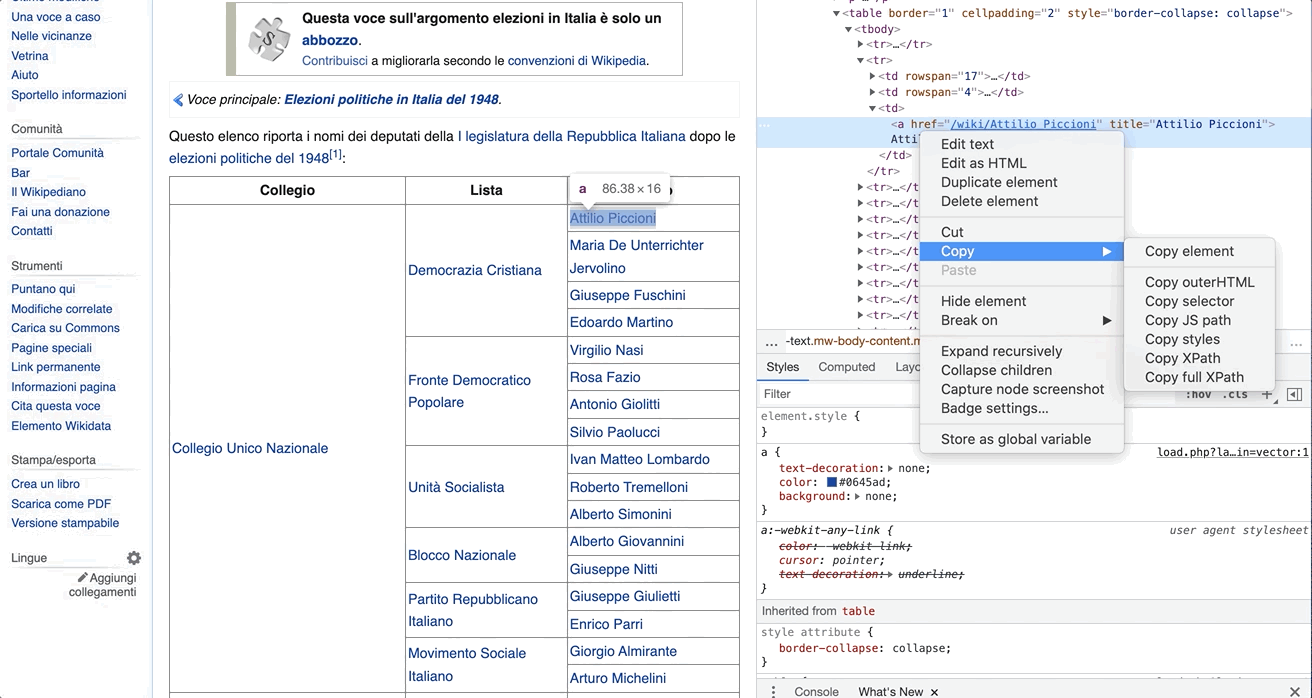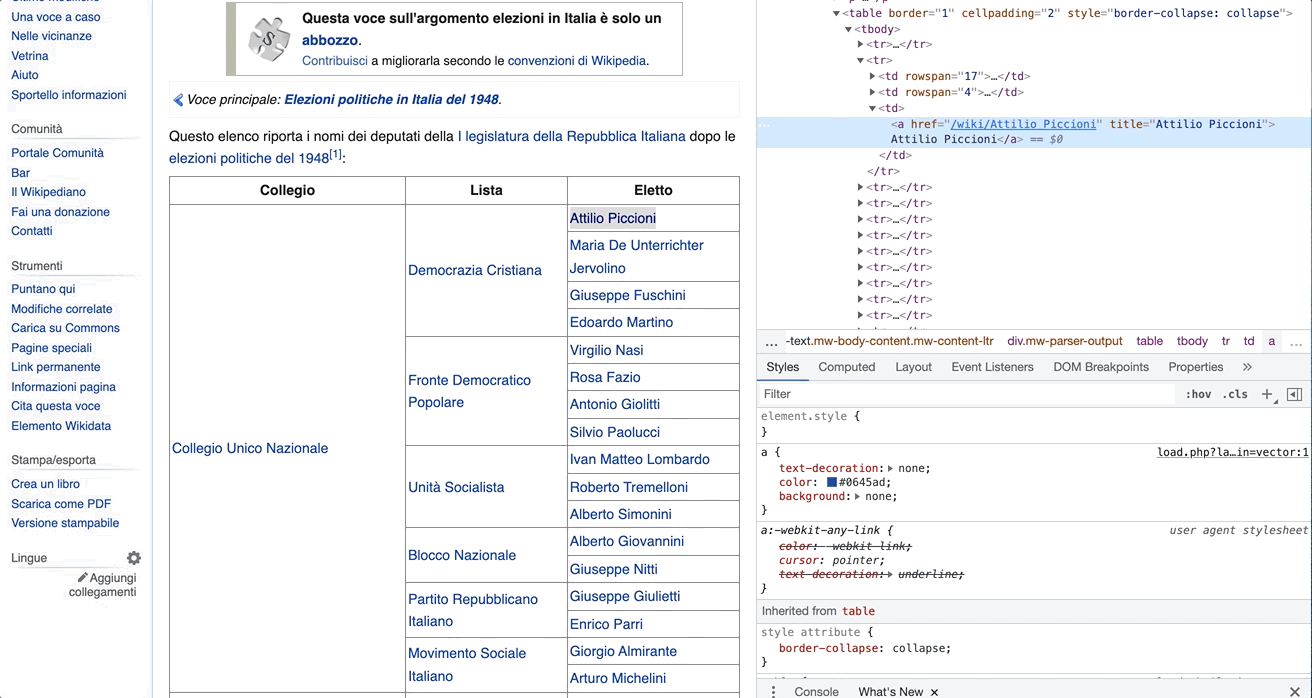
If you right-clicked on it, then copy + Copy XPath, you would get some extra information that would help you in the parsing of the object.
The output XPath to Attilio Piccioni would be: //*[@id="mw-content-text"]/div[1]/table[2]/tbody/tr[2]/td[3]/a
Though criptic initially, this bit of text will serve two purposes:
- as a blueprint to help us understand the underlying structure of the file.
- as a selector to aid us in gathering the attributes we require for our database.
To understand the structure, you can work backwards from //*[@id="mw-content-text"]/div[1]/table[2]/tbody/tr[2]/td[3]/a. For example, you can infer that the <a> tag with Attilio Piccioni’s information is located in the section where id="mw-content-text" (as is the case with the content of most Wikipedia entries). This also tells you that the tag is the third cell of the second row of the second table of the first section.
Selecting with XPaths in R
In a previous step, you created the parsed_html object, which contained the index page as an {html_document} in R. Now, you will learn how to leverage this object to extract the data. To work with the HTML documents, you will employ a couple of functions from the rvest package. Previously, you used rvest::read_html(), which as the name suggest loads HTML files into the environment. At this stage, you will introduce the rvest::html_nodes() function, which extracts nodes from an HTML document based on some selector argument.
This is how the code looked:
parsed_html <- rvest::read_html("data/italy_chamber/html/1948_chamber_session_ITA.html")
parsed_html
## {html_document}
## <html class="client-nojs" lang="it" dir="ltr">
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">\n<meta charset="UTF-8">\n<title>Eletti alla Camera dei deputati nelle elepolitiche italia ...
## [2] <body class="mediawiki ltr sitedir-ltr mw-hide-empty-elt ns-0 ns-subject mw-editable page-Eletti_alla_Camera_dei_deputati_nelle_elezioni_politiche_italiane_del_1948 rootpa ...
You can use rvest::html_nodes() to extract Attilio Piccioni’s information by feeding the XPath into the functions xpath argument, for example:
piccioni <- parsed_html %>% rvest::html_nodes(xpath = "//*[@id='mw-content-text']/div[1]/table[2]/tbody/tr[2]/td[3]/a")
piccioni
## {xml_nodeset (1)}
## [1] <a href="/wiki/Attilio_Piccioni" title="Attilio Piccioni">Attilio Piccioni</a>
You can also get all <a> sections in the table by deleting the specific row and cell markers from the XPath, for example:
node <- parsed_html %>% rvest::html_nodes(xpath = "//*[@id='mw-content-text']/div[1]/table[2]/tbody/tr/td/a")
node
## {xml_nodeset (772)}
## [1] <a href="/wiki/Collegio_unico" title="Collegio unico">Collegio Unico Nazionale</a>
## [2] <a href="/wiki/Democrazia_Cristiana" title="Democrazia Cristiana">Democrazia Cristiana</a>
## [3] <a href="/wiki/Attilio_Piccioni" title="Attilio Piccioni">Attilio Piccioni</a>
## [4] <a href="/wiki/Maria_De_Unterrichter_Jervolino" title="Maria De Unterrichter Jervolino">Maria De Unterrichter Jervolino</a>
## [5] <a href="/wiki/Giuseppe_Fuschini" title="Giuseppe Fuschini">Giuseppe Fuschini</a>
## [6] <a href="/wiki/Edoardo_Martino" title="Edoardo Martino">Edoardo Martino</a>
## [7] <a href="/wiki/Fronte_Democratico_Popolare" title="Fronte Democratico Popolare">Fronte Democratico Popolare</a>
## [8] <a href="/wiki/Virgilio_Nasi" title="Virgilio Nasi">Virgilio Nasi</a>
## ...
You can further tabulate the attributes of the node object into a workable dataframe, as such:
list_table <- tibble::tibble(
url = node %>% rvest::html_attr("href"),
name = node %>% rvest::html_text()
)
list_table
## # A tibble: 772 × 2
## url name
## <chr> <chr>
## 1 /wiki/Collegio_unico Collegio Unico Nazionale
## 2 /wiki/Democrazia_Cristiana Democrazia Cristiana
## 3 /wiki/Attilio_Piccioni Attilio Piccioni
## 4 /wiki/Maria_De_Unterrichter_Jervolino Maria De Unterrichter Jervolino
## 5 /wiki/Giuseppe_Fuschini Giuseppe Fuschini
## 6 /wiki/Edoardo_Martino Edoardo Martino
## 7 /wiki/Fronte_Democratico_Popolare Fronte Democratico Popolare
## 8 /wiki/Virgilio_Nasi Virgilio Nasi
## 9 /wiki/Rosa_Fazio Rosa Fazio
## 10 /wiki/Antonio_Giolitti Antonio Giolitti
## # … with 762 more rows
The new dataframe list_table contains the URLs and text attributes from each <a> node in the table. As you can see, in the previous code chunk, you introduced two additional functions: first) rvest::html_attr() to get specific attributes from a node and second) rvest::html_text() to get the text attached to a node. You could have also extracted the name by getting the title attribute, as such:
tibble::tibble(
url = node %>% rvest::html_attr("href"),
name = node %>% rvest::html_attr("title")
)
## # A tibble: 772 × 2
## url name
## <chr> <chr>
## 1 /wiki/Collegio_unico Collegio Unico Nazionale
## 2 /wiki/Democrazia_Cristiana Democrazia Cristiana
## 3 /wiki/Attilio_Piccioni Attilio Piccioni
## 4 /wiki/Maria_De_Unterrichter_Jervolino Maria De Unterrichter Jervolino
## 5 /wiki/Giuseppe_Fuschini Giuseppe Fuschini
## 6 /wiki/Edoardo_Martino Edoardo Martino
## 7 /wiki/Fronte_Democratico_Popolare Fronte Democratico Popolare
## 8 /wiki/Virgilio_Nasi Virgilio Nasi
## 9 /wiki/Rosa_Fazio Rosa Fazio
## 10 /wiki/Antonio_Giolitti Antonio Giolitti
## # … with 762 more rows
Getting HTML tables into R
As you have seen, the data of interest is located in a <table> node of the <div id="mw-content-text"> section. Fortunately, rvest has a means to easily parse an HTML table into a dataframe, that is: rvest::html_table().
parsed_html %>% rvest::html_table()
## [[1]]
## # A tibble: 1 × 2
## X1 X2
## <lgl> <chr>
## 1 NA Questa voce sull'argomento elezioni in Italia è solo un abbozzo.Contribuisci a migliorarla secondo le convenzioni di Wikipedia.
##
## [[2]]
## # A tibble: 570 × 3
## Collegio Lista Eletto
## <chr> <chr> <chr>
## 1 Collegio Unico Nazionale Democrazia Cristiana Attilio Piccioni
## 2 Collegio Unico Nazionale Democrazia Cristiana Maria De Unterrichter Jervolino
## 3 Collegio Unico Nazionale Democrazia Cristiana Giuseppe Fuschini
## 4 Collegio Unico Nazionale Democrazia Cristiana Edoardo Martino
## 5 Collegio Unico Nazionale Fronte Democratico Popolare Virgilio Nasi
## 6 Collegio Unico Nazionale Fronte Democratico Popolare Rosa Fazio
## 7 Collegio Unico Nazionale Fronte Democratico Popolare Antonio Giolitti
## 8 Collegio Unico Nazionale Fronte Democratico Popolare Silvio Paolucci
## 9 Collegio Unico Nazionale Unità Socialista Ivan Matteo Lombardo
## 10 Collegio Unico Nazionale Unità Socialista Roberto Tremelloni
## # … with 560 more rows
##
## [[3]]
## # A tibble: 3 × 2
## `V · D · M Legislature e parlamentari della Repubblica Italiana` `V · D · M Legislature e parlamentari della Repubblica Italiana`
## <chr> <chr>
## 1 Legislature AC (Eletti) · I · II · III · IV · V · VI · VII · VIII · IX · X · XI · XII · XIII · XIV · XV · XVI · XVII · XVI…
## 2 Deputati I (Eletti) · II (Eletti) · III (Eletti) · IV (Eletti) · V (Eletti) · VI (Eletti) · VII (Eletti) · VIII (Eletti…
## 3 Senatori I (Eletti) · II (Eletti) · III (Eletti) · IV (Eletti) · V (Eletti) · VI (Eletti) · VII (Eletti) · VIII (Eletti…
##
## [[4]]
## # A tibble: 1 × 2
## X1 X2
## <chr> <chr>
## 1 Portale Politica Portale Storia d'Italia
This code retrieves all tables within the parsed_html object. Based on the exploration of the structure from the XPath, you may remember that the information is in the second table. You can extract it like this:
parsed_html %>% rvest::html_table() %>%
magrittr::extract2(2) # to extract table 2 from the nested list
## # A tibble: 570 × 3
## Collegio Lista Eletto
## <chr> <chr> <chr>
## 1 Collegio Unico Nazionale Democrazia Cristiana Attilio Piccioni
## 2 Collegio Unico Nazionale Democrazia Cristiana Maria De Unterrichter Jervolino
## 3 Collegio Unico Nazionale Democrazia Cristiana Giuseppe Fuschini
## 4 Collegio Unico Nazionale Democrazia Cristiana Edoardo Martino
## 5 Collegio Unico Nazionale Fronte Democratico Popolare Virgilio Nasi
## 6 Collegio Unico Nazionale Fronte Democratico Popolare Rosa Fazio
## 7 Collegio Unico Nazionale Fronte Democratico Popolare Antonio Giolitti
## 8 Collegio Unico Nazionale Fronte Democratico Popolare Silvio Paolucci
## 9 Collegio Unico Nazionale Unità Socialista Ivan Matteo Lombardo
## 10 Collegio Unico Nazionale Unità Socialista Roberto Tremelloni
## # … with 560 more rows
This already looks a lot like the expected output for the legislature’s term. If you think back at the first image in this page, you just miss the URL to each legislator’s Wikipedia entry and number of the session. You can do this easily by changing the names of the variables with dplyr::rename(), merging these data with the list_table that contained the URLs, and finally creating a new column with the session name:
parsed_html %>% rvest::html_table() %>%
magrittr::extract2(2) # to extract table 2 from the nested list
dplyr::rename("name" = "Eletto", "constituency" = "Collegio", "party" = "Lista") %>% # change names
dplyr::left_join(., list_table) %>% # join current df with tibble of <a> nodes by name
dplyr::mutate(session = "1")
## Joining, by = "name"
## # A tibble: 572 × 5
## constituency party name url session
## <chr> <chr> <chr> <chr> <chr>
## 1 Collegio Unico Nazionale Democrazia Cristiana Attilio Piccioni /wiki/Attilio_Piccioni 1
## 2 Collegio Unico Nazionale Democrazia Cristiana Maria De Unterrichter Jervolino /wiki/Maria_De_Unterrichter_Jervolino 1
## 3 Collegio Unico Nazionale Democrazia Cristiana Giuseppe Fuschini /wiki/Giuseppe_Fuschini 1
## 4 Collegio Unico Nazionale Democrazia Cristiana Edoardo Martino /wiki/Edoardo_Martino 1
## 5 Collegio Unico Nazionale Fronte Democratico Popolare Virgilio Nasi /wiki/Virgilio_Nasi 1
## 6 Collegio Unico Nazionale Fronte Democratico Popolare Rosa Fazio /wiki/Rosa_Fazio 1
## 7 Collegio Unico Nazionale Fronte Democratico Popolare Antonio Giolitti /wiki/Antonio_Giolitti 1
## 8 Collegio Unico Nazionale Fronte Democratico Popolare Silvio Paolucci /wiki/Silvio_Paolucci_(politico) 1
## 9 Collegio Unico Nazionale Unità Socialista Ivan Matteo Lombardo /wiki/Ivan_Matteo_Lombardo 1
## 10 Collegio Unico Nazionale Unità Socialista Roberto Tremelloni /wiki/Roberto_Tremelloni 1
## # … with 562 more rows
(P.S. No need to worry about list_table containing also the information for the constituencies and the parties, since the join is at the name level.)
Building the collector
As it was said before, a lot of what you will do relies on finding patterns. The job from here is to inspect the index pages and find commonalities. Normally, Wikipedians will maintain a constant format for each legislature. From our experience, only small things change from term to term, such as: the number of the table the information is located in, the headers to introduce the information (e.g. Circoscrizione instead or Collegio), or the number of columns in each table. Still, for the most part you can reuse the code and deal with the exeptions within your collector function.
In this case, the code to extract the information from the 1st session of Camera dei Deputati works for the 2, 3, and 5 sessions. To deal with the exceptions, you can embed conditional expressions within the function stating how to extract information from the pages that are formatted differently.
#### ITALY CHAMBER WIKIPEDIA INFORMATION EXTRACTION =============================================
collectorItalyChamber <- function(paths) {
# import paths to html files in correct order
source <- paths$files
# loop through html files
for (j in 1:length(source)) {
parsed_html <- rvest::read_html(paths$files[j])
node <- parsed_html %>% rvest::html_nodes(xpath = "//*[@id='mw-content-text']/div[1]/table/tbody/tr/td/a")
list_table <- tibble::tibble(url = node %>% rvest::html_attr("href"),
name = node %>% rvest::html_text()
)
if (paths$session[j] %in% c(1,2,3,5)) {
parsed_tab <- parsed_html %>% rvest::html_table() %>% magritrr::extract2(2) %>%
dplyr::rename("name" = "Eletto") %>%
dplyr::left_join(., list_table) %>%
dplyr::select(-contains("Note")) %>%
dplyr::mutate(session = paths$session[j])
} else if (paths$session[j] %in% c(12,13,14)) {
parsed_tab <- bind_rows(parsed_html %>% rvest::html_table() %>% magritrr::extract2(1) %>%
dplyr::rename("party" = "Lista", "name" = "Eletto") %>%
dplyr::select("Circoscrizione", "party", "name"),
parsed_html %>% html_table() %>% magritrr::extract2(2) %>%
dplyr::rename("party" = "Partito", "name" = "Eletto") %>%
dplyr::select("Circoscrizione", "party", "name")) %>%
dplyr::mutate(Circoscrizione = stringr::str_remove(Circoscrizione, regex("^[A-Z]+ - "))) %>%
dplyr::left_join(., list_table) %>%
dplyr::mutate(session = paths$session[j])
} else if (paths$session[j] == 18) {
parsed_tab <- bind_rows(parsed_html %>% rvest::html_table() %>% magritrr::extract2(1) %>%
dplyr::rename("party" = "Lista/Coalizione", "name" = "Eletto") %>%
dplyr::select("Circoscrizione", "party", "name"),
parsed_html %>% html_table() %>% magritrr::extract2(2) %>%
dplyr::rename("party" = "Lista", "name" = "Eletto") %>%
dplyr::select("Circoscrizione", "party", "name"),
parsed_html %>% html_table() %>% magritrr::extract2(4) %>%
dplyr::rename("party" = "Lista", "name" = "Eletto") %>%
dplyr::select("Circoscrizione", "party", "name"),
parsed_html %>% html_table() %>% magritrr::extract2(5) %>%
dplyr::rename("Circoscrizione" = "Ripartizione","party" = "Lista", "name" = "Eletto") %>%
dplyr::select("Circoscrizione", "party", "name")) %>%
dplyr::left_join(., list_table) %>%
dplyr::mutate(session = paths$session[j])
}
else if (paths$session[j] %in% c(15,16,17)) {
parsed_tab <- parsed_html %>% rvest::html_table() %>% magritrr::extract2(1) %>%
dplyr::mutate(Circoscrizione = stringr::str_remove(Circoscrizione, regex("^[A-Z]+ - "))) %>%
dplyr::rename("name" = "Eletto") %>%
dplyr::left_join(., list_table) %>%
dplyr::select(-contains("Note")) %>%
dplyr::mutate(session = paths$session[j])
}
else{
parsed_tab <- parsed_html %>% rvest::html_table() %>% magritrr::extract2(1) %>%
dplyr::rename("name" = "Eletto") %>%
dplyr::left_join(., list_table) %>%
dplyr::select(-contains("Note")) %>%
dplyr::mutate(session = paths$session[j])
}
# collect overall output
if (j == 1) {
output <- list(parsed_tab)
} else {
output <- c(output,
list(parsed_tab))
}
}
return(output)
}