Getting the entities
The first step in this tutorial will be getting the HTML files of the legislatures’ index pages to our machines. We recommend you download the cld-dev folder in your machine to maintain a streamlined workflow and follow this tutorial. Project files in RStudio are self-contained working directories with their own workspace, history and source documents. You can read a bit more about Projects in R here. For this tutorials, we assume some familiarity with R programming and the tidyverse.
In this tutorial, we will illustrate our process with the Italian Chamber of Deputies, or Camera dei Deputati. This code also lives in the code/italian-chamber folder in our sample R Project. You can just open the cld-web.Rproj file to get your R Session started.
The process starts from legislatures’ Wikipedia index pages, for example: the index containing the members elected during the 1948 Chamber elections. From this page, you can also access the indexes of the succesive elections until 2018.
Once you have identified the index for our legislature of interest, you can download them locally. The idea of working with the local HTMLs is to ensure reproducibility since the Wikipedia entries can change.
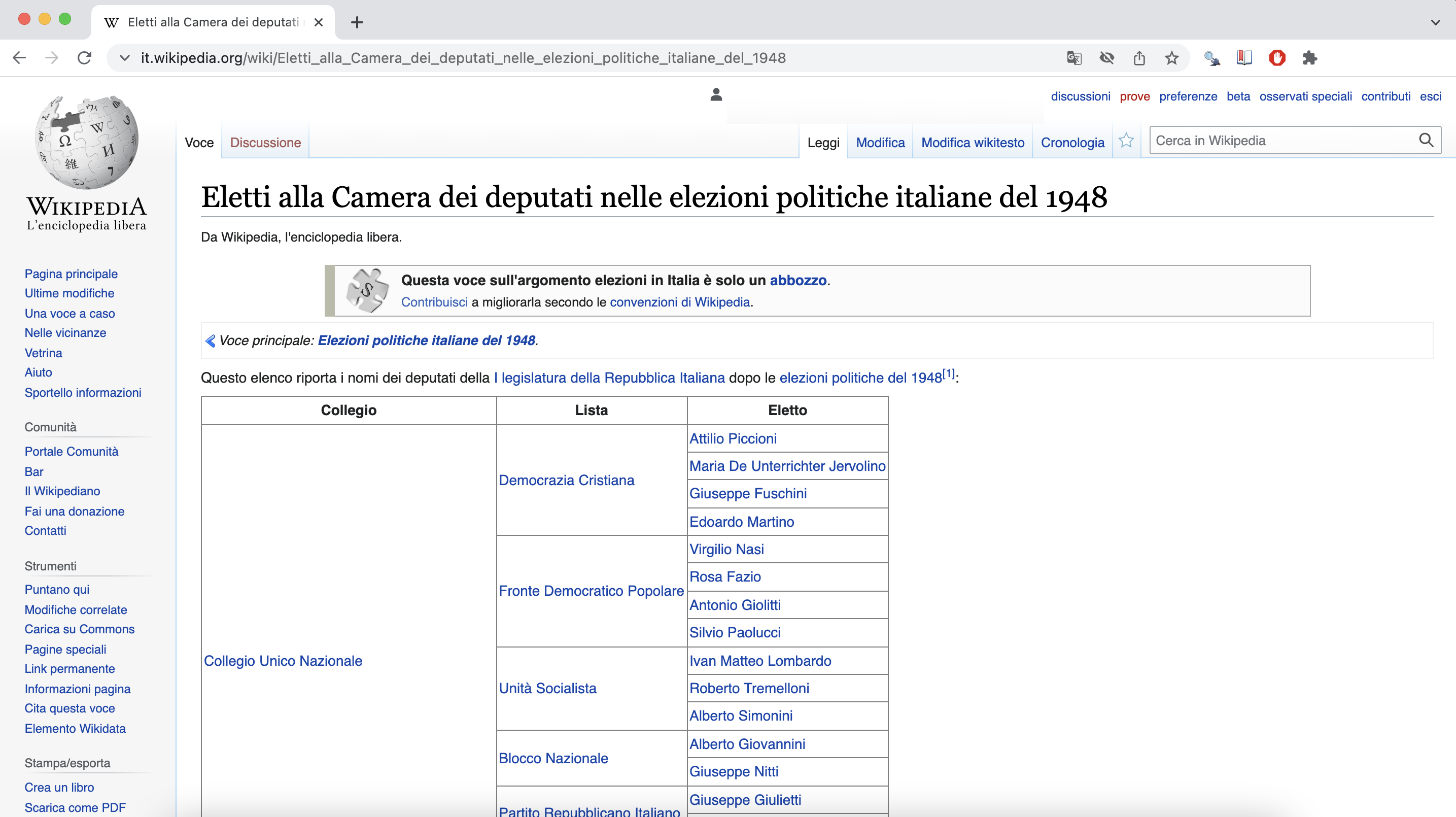
As you will see later, this process relies on finding patterns. At this stage, we would like to look for patterns in the URLs of the index pages to download them. You could also download them one by one manually into your local folder.
In most cases, as it is with the Camera dei Deputati sites, the URL strings are consistent, for example:
- it.wikipedia.org/wiki/Eletti_alla_Camera_dei_deputati_nelle_elezioni_politiche_italiane_del_1948
- it.wikipedia.org/wiki/Eletti_alla_Camera_dei_deputati_nelle_elezioni_politiche_italiane_del_1953
- it.wikipedia.org/wiki/Eletti_alla_Camera_dei_deputati_nelle_elezioni_politiche_italiane_del_1958
Thanks to the conscistency of the URL strings, you can easily create a vector containing the URLs of all the files we would like to download. This reasoning can be adapted to other legislatures. This is how the code would look like:
source("code/packages.R")
source("code/functions.R")
# construct list of urls
## chamber of deputies
leg_ses <- c("1948", "1953", "1958", "1963", "1968", "1972", "1976",
"1979", "1983", "1987", "1992", "1994", "1996", "2001",
"2006", "2008", "2013", "2018") # 1st to 18th sessions
url_list <- glue::glue("https://it.wikipedia.org/wiki/Eletti_alla_Camera_dei_deputati_nelle_elezioni_politiche_italiane_del_{leg_ses}")
file_names <- glue::glue("{leg_ses}_chamber_session_ITA.html")
# download pages
folder <- "data/italy_chamber/html/"
dir.create(folder)
for (i in 1:length(url_list)) {
if (!file.exists(paste0(folder, file_names[i]))) {
download.file(url_list[i], destfile = paste0(folder, file_names[i])) # , method = "libcurl" might be needed on windows machine
Sys.sleep(runif(1, 0, 1))
}
}